
When someone on my team finishes a customer interview, the right summary depends entirely on who's asking. The CEO wants to know if the strategic bet is still paying off. The VP of Product wants to know which feature requirements emerged. The Head of Customer Success wants to know if there's a churn signal. The SDR running outreach wants to know how the customer described the problem in their own words. None of these summaries is wrong. None is complete on its own.
We've quietly accepted, in narrow domains like dashboards and BI reporting, that the same body of underlying data should produce different views for different audiences. We have not extended the same logic to anything else.
Everywhere else in knowledge work, we still produce a single deliverable — the deck, the memo, the status report — and hand it over as if compression into one shape, for one imagined reader, were the entire job. I think this is the most expensive habit in modern knowledge work, and I think it's about to end. The polished deliverable is dying. The context that produced it is the new deliverable.
Every report you've ever sent was a guess
Pause for a moment on what actually happens when you produce a piece of work for someone else. You sit down with everything you know — the data, the conversations, the half-formed thoughts, the three options you considered and discarded, the conversation with a customer that changed your mind, the slide of supporting analysis you cut because of the eight-page limit. Then you compress all of it into a single document, shaped by your guess at what the recipient wants. Then you hand it over. Almost everything else is lost.
Every knowledge worker has lived the consequences. The Friday-evening hand-off where the recipient scans, thanks you, and finds the gap on Monday — and now it's your Monday morning, too. The "thanks for that, I actually only wanted X" message that arrives after three hours of compiling the wrong thing. The follow-up question over Teams that requires you to re-open the entire project to answer.
Underneath all of these is the same mechanic: you're filtering everything you know through your own model of what the recipient wants. The model is almost always wrong, because the people we work with rarely see themselves the way we see them. Just as our self-perception rarely matches how others perceive us, our model of what a colleague needs rarely matches what they actually need. This isn't an edge case. It's the structural condition of communication inside organisations. It happens thousands of times a day in every company I've ever worked with.
The executive summary is a one-way hash. We've been trained to think of compression as efficiency. It isn't. It's a tax we pay because the alternative used to be impossible.
The constraint that justified compression has been lifted
Compression made sense for as long as we were the only ones who could read the source material. If everything I know lives in my head and in a stack of half-organised documents on my desktop, then yes — the only way you'll benefit from any of it is if I painstakingly compress it into something you can absorb in five minutes.
That constraint has quietly disappeared. AI assistants can now read shared folders directly. So when I say context folder, I mean exactly that: a folder in Drive, OneDrive, Notion, or whatever surface your team already lives in, containing the raw material of a piece of work — transcripts, notes, source documents, synthesis as it develops, working hypotheses. The folder isn't a metaphor. It's a literal folder. The shift is that another person, on a different team, can now point their AI at the same folder and produce a different summary, ask a different question, or build a different deliverable from it — without me being in the room and without re-summarising anything.
The standards layer is already forming around this. Engineering teams have begun documenting how AI agents should approach a codebase in a single shared file. Compliance and regulated industries are extending data lineage standards to AI-generated work. ISO/IEC 42001 is making AI governance a board-level question. Every one of these is, at heart, the same recognition: the deliverable alone is no longer sufficient. The context that produced the deliverable is the actual unit of value.
What's missing is the application of this thinking to the kind of work the rest of us do every day. The internal strategy memo. The customer interview. The competitor scan. The board pre-read. The QBR prep. The piece of work where there's no enforced lineage — just one human, compressing what they know into what they hope the next human will need.
What this actually looks like in practice
Last year, my team at Mapp ran a hypothesis-validation programme through customer and partner interviews. The process was completely standard: record the call, transcribe it, summarise the transcript in ChatGPT, paste the summary into Confluence, move on to the next interview. Every strategy team, product team, and customer-facing function I know runs some version of this loop.
What we built this year is structurally different. The validation lives in a OneDrive folder. Inside the folder: a single document explaining the project and our current hypotheses, every interview transcript as a separate file, a synthesis document that gets updated after each call, and a set of reusable instructions we call skills — short prompts that tell our AI assistant how to handle specific tasks consistently. One skill summarises a new transcript against our hypothesis framework. Another compares a new transcript to everything that came before. A third produces a fresh view of the synthesis for a specific audience.
Four things happen now that didn't happen before.
Before each interview, I get a brief on what to listen for. Not a generic checklist — a brief generated from everything we've already learned, telling me which hypotheses are well-validated and need disconfirming evidence, which are thinly supported and need fresh signal, and which assumptions a particular interviewee is best placed to test. The context folder improves the input to the next round of work, not just the output.
After each interview, the new transcript is compared automatically against everything that came before. What did we miss. What did we hear once and never follow up on. What contradicts a previous interview. The gaps surface without me having to ask.
The same folder produces different views for different people. When the CEO asks for an update, the AI projects a progress dashboard from the folder — what's working, what isn't, where we are against the validation plan. When the VP of Product asks the same folder a different question, they get emerging requirements and which prior assumptions are now validated or invalidated. The architects get whether the Whole Product still stacks up. Presales gets messaging that worked, in customers' own words, segmented by persona. Engineers, when they're eventually engaged, can trace any specific use case all the way back to the original hypothesis and the exact moment in a transcript where a customer described the pain.
Same folder. Five views. Zero re-summarisation.
Traceability turns out to be the most important. When an engineer can pull up a use case and follow it all the way back to a customer's exact words, the work becomes auditable, decisions become defensible, and the team stops arguing about whether something is real because the evidence is one click away.
None of this is exotic. The folder is just a folder. The skills are just short instruction documents. What's different is the posture — the decision that the folder is the system, and the documents we hand to people are projections of it.
A new vocabulary will tell you the shift is real

Watch how language changes inside teams that work this way for a few months. The request pattern shifts. People stop asking "can you send me the deck on X." They start asking "can you context-dump me on X."
It sounds throwaway. It isn't. A deck is a single document, polished, frozen at the moment of compression. A context dump is a live, queryable handoff that the recipient can project into whatever shape they actually need.
This is the same kind of shift the language has been through before. "Google it" wasn't just a casual phrase — it was the moment we started expecting the answer to anything to be a search away. "Slack me" reshaped how we expected colleagues to be reachable. New tools produce new request patterns, and the request patterns then produce new norms.
"Context-dump me" does something the previous shifts didn't. It forces the requester to think about what they're actually asking for. You can't context-dump someone in five seconds — you have to define the shape of what you need, the dimensions that matter, the level of depth. The era of "thanks for that, I actually only wanted X" ends, because the act of asking is now itself the act of clarifying.
There's a status implication too. In the old model, the polished summary earned credit. The cleaner the deck, the more senior the work looked. In the new model, the rich, well-structured, properly fueled context is what earns credit. Polish becomes cheap; substance becomes legible.
Context is a vector, not a quantity
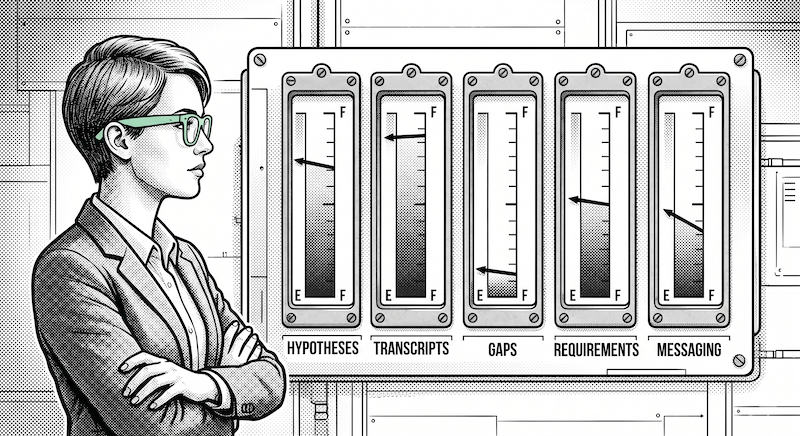
There's a problem the new model creates that the old one didn't, and I want to name it clearly: AI lets you complete in five minutes what looks like it took a day. Without a way to evaluate dimensional quality, slop becomes indistinguishable from substance.
The reports on this are not subtle. Recent estimates suggest more than half of online content is now AI-generated. Studies have found hallucination rates in AI-generated references ranging from 14% to over 90% depending on domain. The single most-cited problem with AI-augmented knowledge work is the illusion of completeness — outputs that look thorough but turn out, on inspection, to be plausible-sounding without being substantive.
The instinct to ask "is this good enough" runs straight into this wall. It's a single-quantity question, answered with a single-quantity vibe check, usually by a recipient too busy to actually evaluate it.
The fix is to stop treating context as a quantity and start treating it as a vector. Context has dimensions. For a customer discovery project, the dimensions might be: hypotheses, interview transcripts, validated claims, gaps, emerging requirements, and messaging by persona. For a competitor analysis: positioning, pricing, case studies, weaknesses, and public commentary. For a QBR: account health signals, expansion opportunities, escalation history, sentiment trend, and forward commitments. The dimensions vary by domain. The principle doesn't: the question worth asking isn't "is this enough" but "across which dimensions am I heavy, medium, light, or missing."
I think about this as a fuel gauge — one needle per dimension, visible to both the producer and the recipient. Heavy on case studies, light on pricing, no competitor data. That's a useful diagnostic. Is this enough? is not.
The fuel gauge solves the Friday-evening problem. When the producer can see, at the moment of handoff, that one dimension is sitting near empty, they know what to flag. When the recipient can see the same gauges, they know where to push and where to trust. The Monday-morning gap discovery disappears, because the gap was visible from the start.
The methodology has to outlive the tool
If everything I've described depends on Cowork, this argument dies the day Cowork is replaced. If it depends on OneDrive, it dies the day your company switches to Drive. The methodology has to be tool-agnostic, or it isn't a methodology — it's a workflow. And workflows die with their tools.
The opportunity worth claiming is a tool-agnostic operating standard for AI-augmented knowledge work. How a context folder is structured. How its contents are evaluated. How it's handed off between people and teams. How different levels of depth are agreed and signalled.
There's good precedent in adjacent fields. Engineering teams have, for years, kept lightweight written records explaining why a particular technical decision was made — these records are tool-agnostic, work in any text editor, and quietly compound in value. Data lineage and provenance standards have moved from regulated-industry compliance into mainstream analytics. ISO/IEC 42001 is being written specifically to be vendor-neutral. None of these are perfect, but all of them solve a version of the same problem we now face in everyday knowledge work: how to make the substance of the work portable across the tools that produce it.
A workable standard has three layers. A structural layer — what a context folder looks like, what files it contains, how it's organised. An evaluative layer — the dimensional fuel gauge, agreed per type of work, with shared definitions of heavy, medium, light, and missing. And a levelling layer — different levels of context proportional to consequence, agreed once at team level, never negotiated per task.
Not every piece of work needs deep context. A two-line Slack reply doesn't need a folder. But every piece of work whose output influences a decision or someone else's work should carry context proportional to its consequence. If the only context you can produce for a task is "because I was asked," that's a tell that the work wasn't understood — not that context wasn't needed.
"I just want three bullets" is a false dichotomy
The most common pushback I get is some version of: I'm a CEO. I want my VP to send me three bullets. That's the whole point of having a VP.
I agree. And the dichotomy is false.
In the new model, you still get the three bullets. The producer still has the responsibility to deliver the answer in the format you asked for. What changes is that the three bullets travel with the substrate that produced them. You can take the bullets at face value, or you can drill in, ask a follow-up that gets answered against the folder rather than re-routed back through the producer, project the same folder into a different view, or hand it to a board member who has different questions than you do.
This is the analytics analogy from a different angle. When someone asks for last quarter's number, you give them the headline. But you'd be furious if your finance team gave you the headline number without the underlying data being available somewhere queryable. We've made our peace with this in BI and finance reporting. The argument is simply that what we've accepted for sales data should become normal for the rest of knowledge work.
One secondary objection worth conceding: sharing your working context exposes your messy thinking. This is true. It's also the point. The shift makes it easier to ask better questions, easier to admit gaps, easier to course-correct early. It's uncomfortable. It produces better work.
Six things you can do this week

If any of this resonates, here's what I'd actually do, starting Monday. None of it requires a tool you don't already have. None of it requires permission from anyone above you in the org chart.
1. Pick one piece of work that recurs. Customer discovery sessions. Quarterly business reviews. Win/loss analyses. Competitor scans. Board pre-reads. Anything you do at least monthly. The repeating shape is what makes the context compounding — the second time you do it, you build on the first; by the fifth time, you have a system. Don't try this on a one-off. Try it on something that will benefit ten times before the year is out.
2. Make a folder, not a document. In Drive, OneDrive, Notion, or whatever surface your team already lives in. Inside the folder, create a simple structure to start with:
- A
READMEdocument at the top level explaining what this project is, what hypothesis or question it's addressing, and who consumes the output. - A
sourcessubfolder for raw inputs — transcripts, screenshots, links, supplier documents, anything you collected. - A
synthesissubfolder for working notes, emerging themes, and your own thinking as it develops. - A
dimensionsdocument listing what "complete" looks like for this kind of work (you'll fill this in step 3). - An
outputssubfolder for the actual deliverables you produce — decks, summaries, emails — each one a projection of the folder.
The folder is the system. The deliverable is just one document inside outputs.
3. Define your dimensions up front. Three to seven dimensions that, together, would constitute fully fueled context for this kind of work. If you're not sure what your dimensions should be, paste this into your AI of choice as a starter:
"I'm working on [type of work — e.g., customer discovery for a new product feature, or quarterly competitor analysis, or QBR prep for a strategic account]. The output is consumed by [audience — e.g., the product team, the exec team, our key account director]. What are the 3–7 dimensions of context I should make sure I cover for this work to be considered complete? For each dimension, describe what it includes and what would constitute heavy / medium / light / missing depth."
The result becomes your dimensions document. Edit it to reflect how your team actually works. The exact list isn't the point — the act of naming dimensions is what makes the rest of the methodology possible.
4. Run one round of fuel-gauge evaluation. After your next deliverable is drafted but before you hand it over, run an evaluation against your dimensions. Paste this into your AI:
"Looking at the contents of this folder against the dimensions defined in
dimensions.md, score each dimension as Heavy, Medium, Light, or Missing. For anything Light or Missing, explain specifically what's thin and what would need to be added to bring it up to Medium or Heavy."
Share the result alongside the deliverable when you hand it over. Two lines is enough: "Here's the deck. Here are the fuel-gauge scores. The pricing dimension is light — flagging now." This single act re-trains the relationship. The recipient learns to look at the gauges before scanning the deck. The producer learns to flag thin sections at the moment of handoff rather than discovering them in a Monday-morning follow-up.
5. Replace one summary request with a context dump. Next time someone asks you for a status update or a summary, send the folder and the bullets. Use a message like:
"Headline view: [three bullets]. Full context folder is here: [link]. Drill in if you want; I can also project a different view if you tell me what shape would help."
The first time you do this, they will probably just read the bullets. The second or third time, when they realise the folder lets them answer their own follow-ups without coming back to you, the relationship changes. Some recipients will start asking for the folder first.
6. Agree levels with your team. Three levels of context, proportional to the consequence of the work:
- Light: a single document with bullets and links to source material. For low-stakes, low-consequence work — internal updates, opinion pieces, quick takes.
- Medium: a folder with the structure described in step 2, dimensions defined, but no formal fuel-gauge evaluation. For day-to-day deliverables — most reports, summaries, and reviews.
- Heavy: a fully fueled folder with dimensions, fuel-gauge evaluation, and traceability back to source material. For decisions that influence strategy, hiring, investment, or external commitments.
Agree the standards once at a team meeting. Document them somewhere everyone can find. Revisit quarterly. Never negotiate per task. The whole point of a standard is that it removes the per-task negotiation that wastes everyone's time.
All six of these compound. The second time you do them, they're easier than the first. By the fifth, they're automatic.
Why I wrote this in the way I wrote it

This article was produced on a 90-minute commute, on a phone, on public transport. I'm telling you this not because I'm fast and not because the AI is impressive — it's both, but neither is the point. Every step in the production of this article was the methodology the article is about. The piece is itself the strongest evidence I can offer for the thesis.
The default approach would have been to draft the blog post first, then strip-mine it for a LinkedIn post, then carve out a few quotes for internal use, then maybe generate a presentation later. Every one of those derivative documents would be a compression of the blog post — which is itself already a compression of my thinking. By the time the onboarding training material was being written six months later, it would be a compression of a compression of a compression of the original thought. It would feel right. It would be wrong.
So I inverted the order. I built the context first, and the deliverables second. There are four upstream documents feeding this article: a brain dump capturing the full thesis with all its branches and counterarguments, a Gemini Deep Research prompt structured around ten dimensions, a fuel-gauge evaluation of the research that came back, and a case study documenting the entire process step by step. The blog post you're reading is one projection of that folder. The LinkedIn post that goes with it is another. The internal team document that turns this into our operating standard is a third. The onboarding training that brings new joiners into our way of working is a fourth.
None of those downstream pieces is a lossy summary of the blog post. Each is drawn directly from the source folder, shaped for its specific audience.
This is the part I most want my peers to take seriously. The order of operations matters. Build the context first. Project it into deliverables second. The compounding only works if the folder is the source. If the deck is the source, every downstream use is a lossy copy of a lossy copy, and the value decays the further it travels.
"Hey Ric, this article is a bit on the long side..."
I know.
I treat my blog the way I treat every other piece of work I described in this article — as a context repository, not a finished deliverable. I expect most of the consumers of what I publish here to be AI agents, including my own.
To give you a sense of how partial what you've just read actually is: the upstream context behind this article — my brain dump capturing the full thesis, the Gemini Deep Research output with its sources and counterarguments, my fuel-gauge evaluation of that research, and the case study documenting the whole process — runs to roughly 50,000 characters. The article you've just read is around 23,000. You're seeing less than half of what produced this piece. The rest lives in my context folder, where it will get projected into other deliverables — the LinkedIn post, internal team documents, onboarding material for new joiners — without being routed through this article first. Each of those will draw directly from the source, not from a compressed copy.
So if you've made it this far and you're thinking I wish this had been shorter, or sharper, or angled at my specific situation — copy the link to this article into the AI chat of your choice and ask for a personalised summary. Tell it your role, your team, the kind of work you do, and what you're trying to figure out. The version it gives you back will be more useful than anything I could have written for a generic reader. That's the whole point.
If you do that, you've just done the thing the article is about. The blog post was one projection. The summary you generated is another. Same context, different view, no re-summarisation needed on my end.
Where this lands
The firms that thrive over the next five years won't be the ones that figured out how to use AI to produce better summaries. They'll be the ones that figured out how to project a singular body of context into the many views their organisation needs. Better summaries are a local optimisation. The context-first shift is a structural one.
The polished deliverable is dying. The context behind it is the new deliverable. The methodology will outlive any specific tool, any specific platform, any specific vendor. The only real question is whether your team adopts a standard before someone else's does.
If only you and I had a standard.


